[C++] The C++ Programming Language: 6. Types and Declarations (3) - Sizes
6.2.4 Integer Types
6.2.5 Floating-Point Types
6.2.6 Prefixes and Suffixes
6.2.7 void
(생략)
6.2.8 Sizes
C++의 기본 자료형의 몇몇 측면, 가령 int의 크기는 구현부에서 정의됩니다. 우리는 이러한 영향을 최소화하기 위한 조치를 취하는 것이 좋습니다. 왜 귀찮게 그렇게 해야 하나요? 다양한 시스템과 다양한 컴파일러 위에서 프로그래밍하기 때문입니다. 만약 이를 신경쓰지 않으면 수많은 버그들을 찾기 위해 시간을 낭비해야겠죠. 호환성은 전혀 신경 쓰지 않고 오로지 하나의 시스템에서만 동작해도 상관 없다고 생각하는 사람들에게는 예외일지 모르겠지만, 이는 분명 현명한 선택은 아닙니다. 여러분의 프로그램이 성공하면, 곧 이식될 것이며, 누군가는 이러한 구현에 종속된 문제들을 찾고 해결해야 합니다. 더 나아가, 프로그램은 종종 같은 시스템을 위해 다른 컴파일러로 컴파일될 필요가 있습니다. 혹은 여러분이 선호하는 컴파일러의 새로운 기능이 배포되고 그것이 현재와는 다른 방식으로 동작하게 될지도 모르죠. 프로그램이 꼬였을 때 그것을 바로잡으려고 하는 것 보다, 사전에 미리 이러한 것들을 고려하는 것이 훨씬 더 쉽습니다.
구현부에 종속적인 언어 기능의 영향을 최소화하는 것은 상대적으로 쉽습니다. 시스템 종속적인 라이브러리 기능의 영향을 최소화하는 것은 꽤 어렵죠. 표준 라이브러리 기능을 최대한 적절한 곳에 활용하는 것이 하나의 접근이 될 수 있습니다.
하나 이상의 정수형, 부호 없는 자료형, 부동 소수점 자료형 등을 제공하는 이유는 프로그래머들이 하드웨어 특성에 맞는 이점을 얻도록 하기 위함입니다. 많은 머신들에서는 메모리 요구사항, 메모리 접근 횟수, 서로 다른 기본 자료형들에 대한 계산 속도 등 두드러지는 차이들이 있습니다. 만약 머신을 안다면, 이들을 어떻게 고려할 것인지 생각하기 쉽겠죠. 가령 적절한 정수 자료형을 선택한다든가 하는 것이죠. 저수준의 기계에 호환 가능하도록 코드를 작성하는 것은 정말로 어려운 일입니다.
다음은 기본 자료형들과 그에 대응하는 리터럴에 대한 시각적 표현입니다.
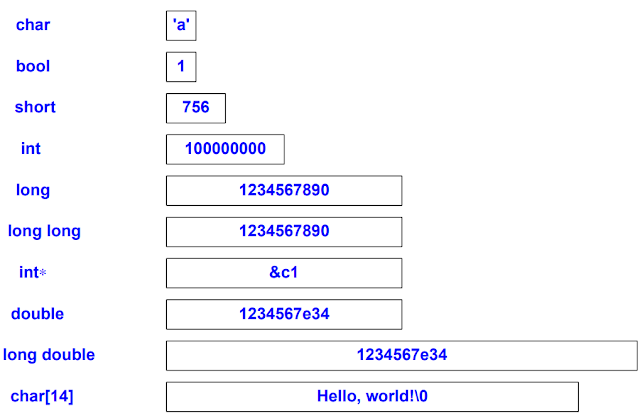
C++ 객체의 크기는 char의 크기의 곱으로 나타나게 됩니다. 즉, 정의에 의해서 char의 크기는 1이 됩니다. 객체의 크기는 sizeof 연산자로 얻을 수 있습니다. 다음은 기본 자료형들의 크기에 대해서 보장되는 것들입니다:

마지막 줄에서 N은 char, short, int, long, long long이 될 수 있습니다. 덧붙여, char는 최소한 8 비트를 지니며, short는 최소한 16 비트를 지닙니다. long은 최소한 32 비트를 갖죠. char 자료형은 주어진 컴퓨터에서 문자를 지니기에 가장 적합하도록 구현부에서 선택됩니다. 보통은 8 비트입니다. 비슷하게, int 자료형 역시 주어진 컴퓨터에 따라 정해지며, 보통 4 바이트입니다. 하지만 이는 절대적인 것이 아닙니다. 어떤 머신의 경우 32 비트의 char를 지닙니다. 특히 int의 크기가 포인터의 크기와 동일하다고 확신하는 것은 매우 바보같은 짓입니다.
기본 자료형에서 구현부에 의해 결정되는 몇몇 측면은 sizeof의 단순한 사례로부터 찾아볼 수 있으며, <limits>에서 더욱 많이 찾아볼 수 있습니다:
1 2 3 4 5 6 7 8 9 10 | #include <limits> #include <iostream> int main() { cout << "size of long " << sizeof(1L) << '\n'; cout << "size of long long " << sizeof(1LL) << '\n'; cout << "largest float == " << std::numeric_limits<float>::max() << '\n'; cout << "char is signed == " << std::numeric_limits<char>::is_signed << '\n'; } | cs |
<limits>의 함수들은 constexpr이며 런타임 오버헤드 없이 활용할 수 있습니다.
기본 자료형들은 대입문과 수식에서 자유롭게 섞어 사용될 수 있습니다. 가능하다면 값은 정보의 손실 없이 변환될 것입니다.
만약 값 v가 자료형 T의 변수로 정확히 표현될 수 있다면, v에서 T로의 변환은 값이 유지됩니다.(value-preserving) 값 보존이 되지 않는 변환은 피하는 것이 좋습니다.
만약 여러분이 특정한 크기의 정수가 필요할 때, 가령 16 비트 정수가 필요하다면 여러분은 표준 헤더인 <cstdint>를 이용할 수 있습니다:

표준 헤더인 <cstddef>는 표준 라이브러리 선언과 유저 코드에서 매우 널리 사용되는 별명(alias)들을 정의합니다: size_t는 구현부에서 정의되는 부호 없는 정수 자료형입니다. 모든 객체의 크기를 바이트로 표현할 수 있죠. 결과적으로, 객체의 크기를 유지하고 싶을 때 사용합니다:
비슷하게, <cstddef>는 부호 있는 정수 자료형 ptrdiff_t를 정의합니다. 이는 두 포인터의 차에 대한 결과를 유지하는데 사용됩니다.
6.2.9 Alignment
(생략)
6.3 Declarations
(생략)


댓글
댓글 쓰기