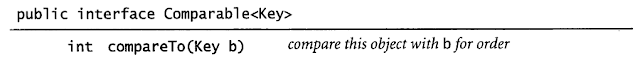[Java] 자바로 프로그래밍 입문하기: 3.3. 자료형 설계하기 (4)

응용프로그램: 데이터 마이닝(data mining) 이번 절에서 논의된 몇몇 개념들을 응용프로그램의 문맥에서 좀 더 설명하기 위해, 우리는 데이터 마이닝 의 어려운 과제를 해결하기에 중요한 소프트웨어 기술에 대해 알아볼 것입니다. 데이터 마이닝 은 웹에서 모든 사용자가 접근할 수 있는 아주 많은 정보들을 검색하는 절차를 기술할 때 널리 쓰이는 용어입니다. 이 기술은 웹 검색 결과의 질적 향상을 극적으로 꾀할 수 있게 만듭니다. 멀티미디어 정보 검색, 바이오메디컬 데이터베이스, 표절 검사, 게놈 연구, 상업 응용프로그램에서의 혁신, 범죄자의 프로파일링 등 다양한 목적으로 사용될 수 있죠. 따라서 아주 주목 받는 분야 중 하나이며, 데이터 마이닝에 대한 연구도 활발히 이루어지고 있습니다. 여러분은 여러분의 컴퓨터에 있는 수천 개의 파일에 직접 접근할 수 있습니다. 또한 웹에 있는 수십억 개의 파일에 우회적으로 접근할 수 있죠. 이 파일들은 아주 다양합니다: 상업 웹 페이지도 있고, 음악과 영상, 이메일, 프로그램 코드 등 다양한 정보를 담고 있죠. 간단하게 생각해보기 위해, 우리는 텍스트 문서에만 집중하도록 합시다.(물론 우리가 고려할 방법은 사진, 음악 등의 파일에도 잘 적용해볼 수 있습니다) 텍스트 문서에만 집중함에도, 여전히 수많은 종류의 문서들이 존재할 것입니다. 우리의 관심은 문서를 특성화하기 위해 콘텐츠 를 사용하여 파일을 검색하는 효율적인 방법을 찾는 것입니다. 이 문제에 대한 생산적인 접근법 중 하나는, 콘텐츠의 기능인 프로필 (profile)이라고 하는 벡터와 각 문서를 연관시키는 것입니다. 이는 곧, 프로필은 문서를 특성화해야 하며, 따라서 문서는 서로 다른 프로필을 가지고, 비슷한 문서는 비슷한 프로필을 가져야 한다는 것입니다. 텍스트 문서들 여러분은 아마 이 접근법이 소설과 자바 프로그램, 게놈 사이를 구별할...